
À l’heure actuelle, Google a annoncé l’introduction délibérée de son champ inhabituel de VM « Tau », ou T2D, de ses offres de VM Google Compute Engine. Le matériel contient les processeurs Milan inhabituels d’AMD, ce qui est un ajout bienvenu aux offres de Google.
En revanche, l’information idéale de l’annonce de ce jour n’était pas Milan, mais la réalité de ce que fait Google en termes de vCPU, son impact sur l’efficacité et les conséquences sur la situation d’approvisionnement des fournisseurs de cloud computing, en particulier dans le contexte de la concurrence inhabituelle des CPU de serveur Arm.
En commençant par le niveau d’information idéal que Google présente aujourd’hui, on constate que les VMs inhabituelles de GCP Tau présentent un soutien d’efficacité stupéfiant par rapport aux offres concurrentes d’AWS et Azure. Les comparaisons VMs petit tirage publié ici :
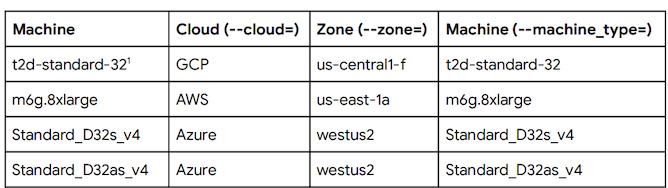
La méthodologie SPECrate2017_int de Google imite en grande partie notre utilisation intérieure de la suite de tests en termes de drapeaux (une paire de différences savourent LTO et le lien d’allocateur), néanmoins la résolution idéale descend de la divulgation des compilateurs, avec Google soulignant que le soutien d’efficacité de +56% sur Graviton2 d’AWS vient d’un bustle AOCC. Ils exposent en outre qu’un compilateur GCC atteint une efficacité de +25%, ce qui clarifie certains aspects :
Bien que nous ayons également examiné avec GCC l’utilisation de -O3, nous avons constaté une meilleure efficacité avec -Ofast sur toutes les machines examinées. Une philosophie intéressante est que, alors que nous avons remarqué une augmentation de 56% de l’efficacité estimée SPECrate®2017_int_base sur le t2d-non contemporain-32 par rapport au m6g.8xlarge après avoir utilisé le compilateur d’optimisation d’AMD, qui pourrait éventuellement par chance obtenir le soutien de l’architecture AMD, nous avons également remarqué une augmentation de 25% de l’efficacité sur le t2d-non contemporain-32 par rapport au m6g.8xlarge lorsque l’utilisation de GCC 11.1 avec les drapeaux ci-dessus pour chaque machine.
Ayant cette résolution de 25% à l’esprit, nous sommes en mesure de descendre abet à notre maintenir l’information examinée en interne de la Graviton2 ainsi que le plus pas trop longtemps précédemment examiné AMD Milan fleuron pour un positionnement difficile de la situation :
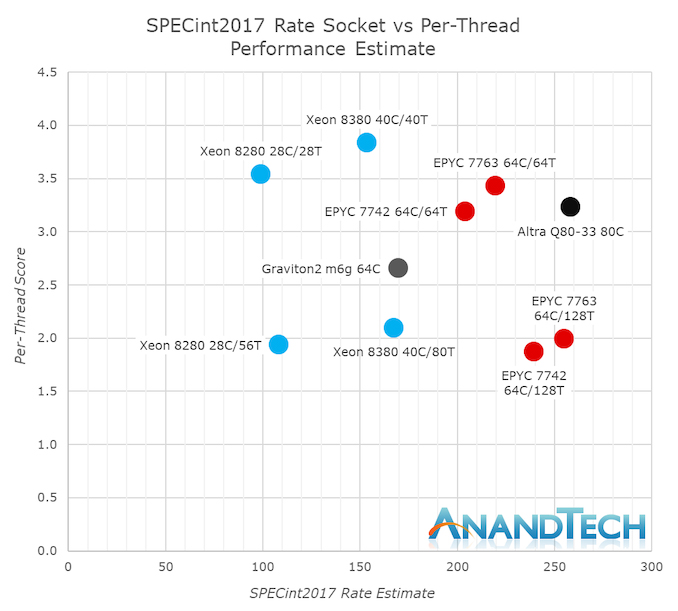
Google n’expose pas de petits caractères d’imprimerie de ce que plus ou moins SKU ils essaient, d’autre part nous avons absorbé des informations vCPU 64-core et 32-core sur Graviton2, marquant des scores estimés de 169.9 et 97.8 avec des scores par thread de 2.65 et une paire de .16. Nos chiffres intérieurs d’un processeur AMD EPYC 7763 (64 cœurs 280W) montrent une obtention estimée de 255 prix et 1,99 par thread avec SMT, et 219 prix et 3,43 par thread pour respectivement 128 threads et 64 threads par socket. La réduction des scores en se basant essentiellement sur un nombre de threads de 32 – essentiellement basé sur ce que Google indique ici comme vCPUs pour l’instance T2D, nous amènerait à des scores de 63,8 avec SMT, ou 109,8 sans SMT. Le buste SMT avec 32 threads serait peut-être par chance particulièrement moins performant que le Graviton2, tandis que le buste sans SMT serait peut-être par chance plus efficace de 12 %. Nous estimons que les scores spécifiques dans une ambiance 32-vCPU avec moins de charge sur le reste du SoC serait peut-être par chance vraisemblablement particulièrement augmenté, et cela correspondrait à peu près à l’efficacité citée par la société +25 soutien.
Et c’est là que se trouve le choc astronomique de l’annonce de ce jour : pour que les chiffres d’efficacité inhabituels de Google Milan aient un sens, il faudrait qu’ils indiquent qu’ils sont l’utilisation de cas avec des nombres de vCPU qui correspondent en vérité à la dépendance du noyau corporel – ce qui a d’énormes implications sur l’évaluation comparative et les comparaisons d’efficacité entre les cas d’une dépendance vCPU égale.
Sérieusement, à propos de l’anecdote de Google qui se spécialise dans la comparaison de Graviton2 à AWS, j’interprète cela comme une attaque directe et une réponse aux affirmations d’Amazon et d’Arm sur l’efficacité des nuages en ce qui concerne les VM avec une option donnée de vCPU. Bien sûr, même après avoir examiné le Graviton2 l’année dernière, nous avons philosophé sur cette divergence dès que l’on compare les offres de VM en nuage aux offres en nuage x86 qui absorbent le SMT et où une vCPU signifie en réalité que vous obtenez un noyau logique plutôt qu’un noyau physique, comme c’est le cas pour le Graviton2 plus récent, basé essentiellement sur Arm. En fait, nous avons évalué les CPU Arm avec un nombre de cœurs double de celui des processeurs x86 sur les tailles d’instances liées. En réalité, voici en toute tranquillité ce que fait Google aujourd’hui en comparant une VM Milan Tau de 32vCPU à une VM Azure Cascade Lake de 32vCPU – il s’agit d’une comparaison 32 cœurs contre 16 cœurs, le SMT étant activé dans ce dernier cas.
Étant donné que Google égalise désormais la situation par rapport aux cas de VM entièrement Graviton2 basées sur l’architecture Arm à dépendance vCPU égale, en disposant en réalité de l’option liée de cœurs physiques, il n’a aucun composant à concurrencer en termes d’efficacité avec le concurrent Arm et, naturellement, il surpasse également les différentes alternatives de fournisseurs de cloud computing où un vCPU est l’idéal tranquille d’un CPU SMT logique.
Google propose une instance T2D de 32 vCPU avec 128 Go de RAM à 1,35 USD par heure, contre une instance AWS liée de m6g.8xlarge avec également 32 vCPU et 128 Go de RAM à 1,23 USD par heure. Bien que l’utilisation par Google de l’AOCC pour obtenir des chiffres d’efficacité accrus par rapport à nos chiffres GCC joue un certain rôle, et que l’efficacité de Milan soit énorme, c’est sans doute la réalité que nous semblons maintenant comparer des cœurs physiques à des cœurs physiques qui rend sans doute les cas inhabituels de Tau VM particuliers par rapport aux offres d’AWS et d’Azure (physiques à logiques dans ce dernier cas).
Dans l’ensemble, j’applaudis l’initiative de Google dans ce domaine, car le fait de se voir offrir la part idéale d’un cœur en tant que vCPU était jusqu’à présent une véritable arnaque. Dans un sens, nous devrions également remercier la concurrence inhabituelle d’Arm pour avoir finalement transféré l’écosystème dans ce qui semble être le début de l’arrêt de telles pratiques douteuses de vCPU et d’offres de VM. Il n’aurait pas non plus été possible de maintenir les offres inhabituelles d’AMD en matière d’unités centrales de traitement à cœur énorme. Il sera intéressant de voir comment AWS et Azure vont réagir à long terme, car je maintiens que Google est en train de bouleverser le marché du cloud en termes de prix et de tarifs.